如何利用Snipaste实现OCR文字识别与截图文本提取 #
在信息爆炸的数字时代,我们每天都要与海量的文本、图像信息打交道。无论是从一份PDF报告、一张网页截图、一个软件界面,还是一段视频画面中提取关键文字信息,手动输入不仅效率低下,而且极易出错。此时,光学字符识别(OCR)技术便成为了连接图像世界与文本世界的桥梁。你可能知道Snipaste是一款卓越的截图工具,但其内置的OCR功能,才是它从众多截图软件中脱颖而出的“效率倍增器”。本文将为你全面、深入地解析如何利用Snipaste高效、精准地实现OCR文字识别与截图文本提取,将静态图片中的文字瞬间转化为可编辑、可搜索、可复用的数字文本。
一、Snipaste OCR功能核心优势:为何选择它? #
在深入实操之前,我们有必要了解Snipaste的OCR模块相较于独立OCR软件或在线识别网站的核心优势。这不仅能帮助你理解其价值,也能在后续使用中更好地扬长避短。
- 无缝集成于截图工作流:这是Snipaste OCR最核心的优势。你无需“截图->保存->打开另一个OCR软件->导入图片”这样繁琐的流程。在Snipaste截图后,直接进入标注工具栏即可触发OCR,真正做到“所见即所识”,流程无缝衔接,效率提升数倍。
- 极致速度与隐私安全:所有识别过程均在本地完成,无需将可能包含敏感信息的截图上传至任何第三方服务器。这确保了数据处理的速度(毫秒级响应)和绝对的隐私安全,对于处理商业文档、个人信息的用户至关重要。
- 高精度识别与多语言支持:得益于先进的本地OCR引擎,Snipaste对印刷体文字的识别准确率非常高。它支持识别包括中文(简/繁)、英文、日文、韩文、俄文、法文、德文、西班牙文等在内的多种语言,并能自动检测语言类型,满足国际化工作需求。
- 识别结果即时编辑与使用:识别出的文本不仅显示在预览框中,更可以直接进行编辑(修正可能的识别错误)、一键复制到剪贴板,或直接保存为文本文件。这种“识别-修正-输出”的一体化体验,让信息流转无比顺畅。
- 免费且无任何限制:作为Snipaste免费版的核心功能之一,OCR没有任何使用次数、识别字数或功能上的阉割,用户可以无负担地长期使用。
二、Snipaste OCR功能全流程实操指南 #
掌握正确的操作流程是发挥其效能的基础。本节将分步详解从截图到文本提取的完整过程。
第一步:触发截图与进入OCR模式 #
- 启动截图:使用默认快捷键
F1(可自定义)启动Snipaste截图。精准框选包含你所需文字的区域。 - 进入标注模式:截图完成后,不要直接保存或取消。此时,截图界面会悬浮在屏幕最前端,并自动弹出标注工具栏。如果你的工具栏未自动弹出,可点击截图窗口。
- 定位OCR按钮:在标注工具栏中,找到 “文本” 图标(一个“T”字母的图标)。将鼠标悬停在该按钮上,工具提示会显示“文本识别 (T)”。请注意:在早期版本或某些界面下,它可能被直接标识为“OCR”。点击此按钮。
第二步:执行OCR识别与查看结果 #
点击“文本识别”按钮后,Snipaste会瞬间完成OCR处理。处理结果会以一个半透明的文本预览框形式,覆盖在原截图区域附近。
- 预览框内容:框内清晰展示识别出的纯文本。
- 预览框工具栏:预览框上方或下方会提供几个关键操作按钮,通常包括:
- 复制:将识别出的全部文本复制到系统剪贴板。
- 编辑:进入文本编辑模式,允许你修改识别有误的字词。
- 保存:将文本保存为
.txt文件。 - 关闭:关闭预览框。
第三步:后期处理与文本输出 #
识别完成并非终点,高效的后处理才能确保信息的最终可用性。
- 快速修正错误:识别不可能100%准确,尤其是面对低分辨率、特殊字体或复杂背景的图片时。立即点击 “编辑” 按钮,在文本框内直接修改错别字或调整格式(如删除多余空格、换行)。养成“识别后快速校对”的习惯,能省去后续大量整理时间。
- 一键复制与应用:校对无误后,点击 “复制”。随后,你可以将其粘贴到任何需要的地方:Word文档、Excel表格、浏览器搜索框、聊天窗口、代码编辑器等。这是最常用的输出方式。
- 保存为独立文件:如果需要将提取的文本归档,点击 “保存”,选择路径和文件名即可保存为TXT文件。对于需要批量处理或长期存储的文本信息,这非常有用。
- 直接拖拽使用(高级技巧):Snipaste识别出的文本预览框,其内容可以直接被部分支持拖拽的应用捕获。例如,你可以尝试从预览框中拖拽文本到记事本或Word中。
三、Snipaste OCR高级应用场景与技巧 #
仅仅会基础操作还不够,将OCR功能融入具体的工作场景,并掌握一些高阶技巧,才能将其威力最大化。
场景一:学术研究与资料整理 #
- 从扫描版PDF或电子书中摘录:许多学术著作只有扫描版PDF,无法直接复制文字。使用Snipaste对PDF阅读器(如Adobe Acrobat、Edge浏览器)中的页面进行截图并OCR,即可快速摘录论点、数据、参考文献,便于建立个人知识库。
- 整理网页研究资料:遇到禁止复制或格式复杂的网页时,直接截图所需段落进行OCR,可以干净地提取纯文本,避免附带超链接和杂乱格式。
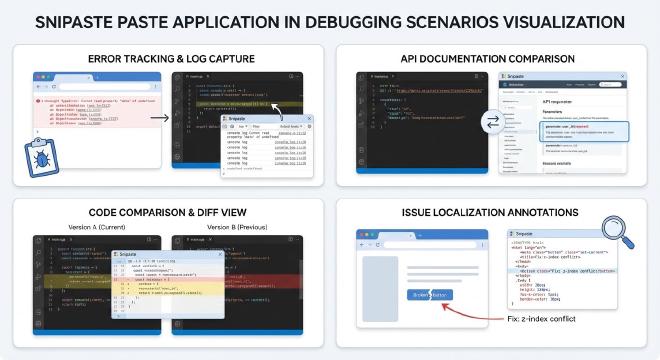
场景二:编程与开发调试 #
- 提取错误信息与日志:当软件弹出错误对话框、命令行窗口显示报错日志时,这些信息往往无法直接选中复制。快速截图进行OCR,能立即将错误代码、异常堆栈信息转化为文本,方便搜索解决方案或粘贴到求助论坛。这与《Snipaste贴图功能在编程与代码调试中的高效应用》一文中提到的技巧相结合,能构建强大的调试工作流。
- 从UI界面中获取文本资源:在软件本地化、界面检查或自动化测试中,需要核对界面上的所有文字。OCR可以快速提取按钮标签、菜单项、提示文本等。
场景三:外语学习与翻译辅助 #
- 即时翻译生词与句子:阅读外文网站或文档时,遇到不理解的句子,截图后OCR提取文本,然后复制到翻译软件(如DeepL、Google翻译)中,比手动输入快得多。
- 制作外语词汇表:从外语材料中批量截图生词或例句,通过OCR提取文本后,集中整理到Anki等记忆软件中制作学习卡片。
场景四:办公与行政管理 #
- 快速录入表格数据:对于简单格式的、无法导出的图片表格,可以按行或列截图,OCR提取数据后,再粘贴到Excel中稍作调整,比手动录入快数倍。注意:复杂合并单元格或手写表格识别效果不佳。
- 处理会议纪要白板照片:会议后拍摄的物理白板照片,可以用Snipaste进行OCR,将手写要点(要求字迹清晰)或打印体内容转化为电子纪要草稿。
高级技巧与设置优化 #
- 快捷键自定义:为了更快地触发OCR,你可以在Snipaste设置中,为“截图后工具”或直接为“文本识别”功能分配一个独立的快捷键。例如,设置为
Ctrl+Shift+T,这样截图后无需鼠标点击工具栏,直接按快捷键即可识别。 - 结合贴图功能进行多源信息对比:这是Snipaste的“杀手级”组合技。将来源A的文本截图后,不直接OCR,而是先按
F3将其贴图固定在屏幕一侧。再对来源B的文本截图并OCR。这样,两份文本可以同屏并置,方便进行逐字逐句的对比、校对或整合。关于贴图的创造性用法,你可以参考《提升工作效率:Snipaste贴图功能的10个创造性使用场景》获取更多灵感。 - 处理低质量图像的技巧:如果原图模糊、对比度低,可以先用Snipaste的标注工具进行简单预处理。例如,使用“矩形”工具框选重点区域以排除干扰,或先截取更大区域再在OCR前于预览框内放大,有时能提升识别成功率。
- 识别结果格式化处理:OCR识别出的文本可能带有不必要的换行和空格。Snipaste的编辑框虽然简单,但你可以将文本复制到支持正则表达式查找替换的编辑器(如VS Code、Notepad++)中进行快速清洗和格式化。
四、Snipaste OCR的局限性及应对方案 #
没有技术是万能的,了解边界才能更好地使用工具。
- 手写体识别能力有限:Snipaste的本地OCR引擎主要针对印刷体优化。对于连笔、潦草的手写文字,识别准确率会显著下降,甚至无法识别。应对方案:对于重要手写内容,考虑使用专门的手写OCR在线服务(如Google Keep的手写笔记识别)或手机APP(如微软Office Lens)。
- 复杂排版与特殊格式丢失:OCR输出的是纯文本,原图中的字体、颜色、大小、图片、表格结构(合并单元格)、复杂的多栏排版等所有格式信息都会丢失。应对方案:对于需要保留格式的文档,优先寻找源文件或使用Adobe Acrobat Pro等专业PDF工具进行转换。对于表格,可尝试专门的表格OCR工具。
- 识别精度受源图像质量影响:图像分辨率过低、背景杂乱、光线不均、文字倾斜角度过大都会影响识别精度。应对方案:截图时尽量保证原画面清晰,通过调整截图范围确保文字区域占据主要部分。必要时,可先使用图片编辑软件调整对比度和亮度。
- 批量处理能力不足:Snipaste OCR设计为交互式、单次操作,不具备自动批量处理大量图片文件的能力。应对方案:需要批量识别大量扫描件时,应使用具备批量功能的专业OCR软件,如ABBYY FineReader,或编写脚本调用云OCR API(如百度、腾讯的OCR接口)。
五、Snipaste OCR与其他工具链的整合 #
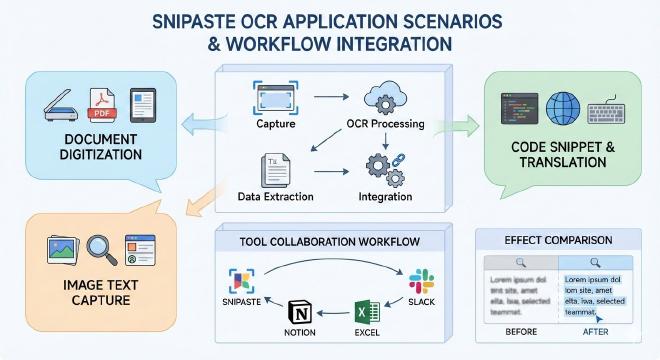
将Snipaste作为你工作流中的一环,与其他工具配合,能构建更强大的自动化管道。
- 与文本编辑器/IDE整合:OCR提取代码或配置文本后,直接粘贴到VS Code、Sublime Text等编辑器,利用其语法高亮和代码格式功能进行美化。
- 与剪贴板管理器配合:使用Ditto、CopyQ等剪贴板管理器,可以保存Snipaste OCR复制出的所有文本历史,方便后续回溯和复用,避免因多次复制导致的信息丢失。
- 与自动化工具联动(进阶):通过Windows的PowerShell或第三方自动化软件(如AutoHotkey),可以模拟按键序列,将“截图->OCR->复制->粘贴”这一系列操作部分自动化,用于高度重复的特定任务。
六、常见问题解答 (FAQ) #
Q1: Snipaste OCR功能识别中文出现乱码或错误怎么办? A1: 首先,确保你的Snipaste为最新版本。其次,在识别前,尝试在设置中明确指定识别语言为“简体中文”或“中文(自动检测)”。如果问题依旧,检查源图片质量,并尝试使用编辑功能手动修正。少数情况下,极特殊的艺术字或古字体可能无法被准确识别。
Q2: 能否识别图片中的数学公式或化学方程式? A2: 不能。Snipaste的OCR是通用的文本识别引擎,无法识别复杂的数学公式、化学式等专业符号。这类内容会被识别为无意义的字符或直接忽略。需要识别公式,请使用专为STEM领域设计的工具,如Mathpix Snip。
Q3: Snipaste OCR在Mac版和Windows版上有差异吗? A3: 核心OCR功能在两个平台上保持一致,都具备高精度和本地识别的特点。但由于系统底层架构不同,快捷键、界面布局和部分交互细节可能存在细微差异。建议分别熟悉各自平台的操作,你可以阅读《Windows与Mac系统下截图工具Snipaste的详细对比评测》来了解更详细的跨平台特性对比。
Q4: 识别出的文本如何快速去除多余的空格和换行符?
A4: Snipaste内置的编辑功能较为基础。最佳实践是:先将文本复制到专业的文本编辑器(如Notepad++、VS Code、Sublime Text)。使用这些编辑器的“查找和替换”功能,利用正则表达式匹配 \s+(多个空白字符)替换为单个空格,匹配 \n+(多个换行)进行规整,可以高效地清洗文本格式。
Q5: 我的工作需要处理大量多语言文档,Snipaste OCR支持混合语言识别吗? A5: 支持。Snipaste的自动语言检测功能在处理中英混杂、日英混杂等常见混合文本时表现良好。对于非拉丁语系与拉丁语系的混合(如中文中夹杂英文单词),准确率很高。如果遇到识别不理想的情况,可以手动在设置中指定主要语言。
结语 #
Snipaste的OCR文字识别功能,绝非一个简单的附加特性,而是将其从一款优秀的截图工具升级为“信息捕手与转换中枢”的关键。它完美诠释了“工具服务于流程”的理念,将截图这一捕捉动作,与文本提取这一转化动作,以近乎零成本的方式无缝融合。通过本文的详解,希望你不仅掌握了从点击按钮到获取文本的基础操作,更能理解其在不同工作场景下的灵活应用,洞悉其优势与边界,并开始思考如何将其与你的个人工作流深度整合。
从快速抓取网页片段到解码软件错误日志,从辅助外语学习到整理研究笔记,Snipaste OCR正在悄然改变我们处理图像化信息的方式。它让我们不再受制于“无法复制”的枷锁,极大地释放了信息自由流动的潜力。现在,就按下 F1,开始你的高效文本提取之旅吧。欲进一步挖掘Snipaste的潜能,例如掌握其全面的快捷键以提升整体操作速度,推荐你继续阅读《Snipaste快捷键大全:从入门到精通的终极快捷键指南》,将你的工作效率推向新的高度。
本文由Snipaste官网提供,欢迎浏览Snipaste下载网站了解更多资讯。